
La caída de AWS en octubre de 2025: lo que realmente nos enseña


El 20 de octubre de 2025, Amazon Web Services (AWS) sufrió una de sus interrupciones más importantes en años. La región US-EAST-1, ubicada en Virginia del Norte, estuvo fuera de servicio durante casi 15 horas, afectando a más de 70 000 organizaciones y generando más de 8 millones de reportes de fallas en todo el mundo. Aplicaciones como Slack, Snapchat, Fortnite, Roblox, Coinbase y Robinhood dejaron de funcionar, junto con sistemas bancarios y gubernamentales críticos.
Como siempre, la caída desató debates: algunos defendieron volver a los data centers locales (on-premise), otros insistieron en que la solución es el multi-cloud. Ambas posturas pierden de vista la verdadera lección.
Las caídas son inevitables
Ningún sistema a gran escala está libre de fallos. AWS ha tenido pocas interrupciones importantes en casi dos décadas (2011, 2015, 2017, 2019, 2021, 2023 y ahora 2025). Ese historial, considerando miles de millones de horas de cómputo, es tremendamente sólido. Pero la complejidad de la infraestructura digital moderna garantiza que las caídas volverán a ocurrir, tanto en cloud como en on-premise.
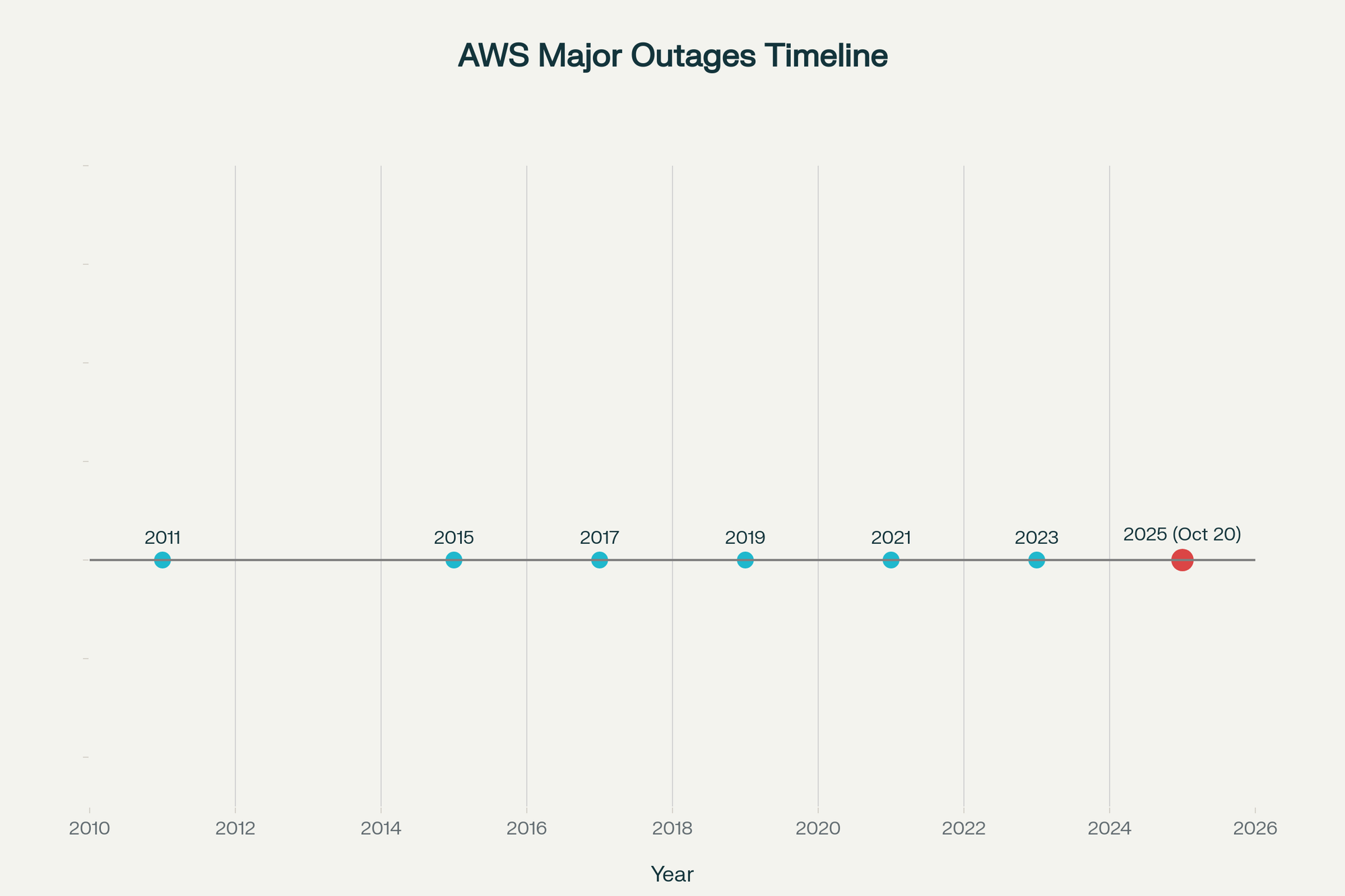
Las organizaciones deben diseñar asumiendo esa inevitabilidad. Las arquitecturas, procesos y modelos operativos tienen que anticipar el tiempo fuera de servicio, no pretender que puede eliminarse.
¿Qué ocurrió en US-EAST-1?
La causa raíz fue una falla en la resolución DNS que afectó a los endpoints del API de DynamoDB. Esto provocó fallos en cadena en 113 servicios de AWS. El problema se agravó porque US-EAST-1 no es solo otra región: es la más antigua y sobrecargada, con dependencias del control-plane global que generan efectos dominó en todo el mundo.
La recuperación necesitó no solo corregir el DNS, sino también limpiar enormes colas de solicitudes y restaurar sistemas dependientes. Todo el proceso tomó alrededor de 15 horas.
El mito del on-premise
Las caídas en la nube son más raras y menos catastróficas
Algunos afirmaron que esto demuestra que se debe volver a la infraestructura on-premise. Los datos muestran lo contrario:
- AWS y otros hyperscalers ofrecen garantías de disponibilidad superiores al 99.9 %, es decir, menos de 9 horas de inactividad al año.
- Invierten miles de millones —82 mil millones solo en el Q3 2024— en redundancia y seguridad.
- La mayoría de las organizaciones no puede igualar ese nivel de resiliencia. Construir data centers redundantes, contratar personal especializado y mantener procesos de disaster recovery es demasiado costoso.
En términos estadísticos, las caídas en la nube son más raras y menos catastróficas que las que sufrirían la mayoría de las empresas gestionando su propia infraestructura.
La trampa de la complejidad multi-cloud
Un verdadero esquema active-active entre nubes es raro, caro y, en muchos casos, innecesario.
Otros argumentaron que la solución es adoptar múltiples nubes. Si bien distribuir cargas entre proveedores puede reducir la dependencia y diversificar riesgos, también introduce desventajas importantes:
- Costos: personal especializado, herramientas adicionales y pérdida de descuentos.
- Complejidad: el 73 % de las organizaciones afirma que el multi-cloud aumentó su complejidad operativa.
- Interoperabilidad: diferentes APIs, formatos y modelos de seguridad.
La mayoría de las estrategias multi-cloud no ejecutan el mismo servicio en varias nubes, sino que distribuyen diferentes sus servicios entre varias nubes. Un verdadero esquema active-active entre nubes es raro, caro y, en muchos casos, innecesario.
Las verdaderas lecciones
Esta caída deja lecciones más valiosas que “vuelve al on-prem” o “usa multi-cloud para todo”:
- La arquitectura importa más que la ubicación. Diseñar para caídas de una región completa, no solo de zona de disponibilidad, es clave. Las arquitecturas multi-region o pilot-light son esenciales para cargas críticas. En Oka, por ejemplo, decidimos usar US-EAST-2 como región principal en lugar de US-EAST-1, sabiendo que esta última estaba sobrepoblada y presentaba mayor riesgo. Esa decisión redujo el impacto durante la caída. Aun así, algunas dependencias externas en US-EAST-1 generaron fricciones, demostrando que la arquitectura puede reducir exposición, pero no eliminar el riesgo.
- Las dependencias en cascada son el enemigo. Como se vio en la caída de Facebook en 2021 y en el incidente de CrowdStrike en 2024, los sistemas estrechamente acoplados fallan juntos. Mapear dependencias y probar diferentes escenarios de caídas es clave.
- La preparación supera la teoría. Las organizaciones que prueban sus planes de recuperación de manera regular se recuperan hasta un 50 % más rápido. La chaos engineering y los simulacros realistas aportan más valor que la redundancia teórica.
- El análisis costo-beneficio es clave. Las interrupciones son caras —se estiman entre 38 y 581 millones de dólares en pérdidas aseguradas y 75 millones por hora en impacto operativo—, pero construir resiliencia equivalente on-premise cuesta mucho más.
La realidad de la nube
A pesar de los titulares, la adopción de la nube sigue creciendo. El mercado global avanza a un ritmo del 25 % anual y superará los 400 mil millones de dólares este año. AWS (30 %), Azure (20 %) y GCP (13 %) dominan gracias a su escala, infraestructura global y velocidad de innovación.
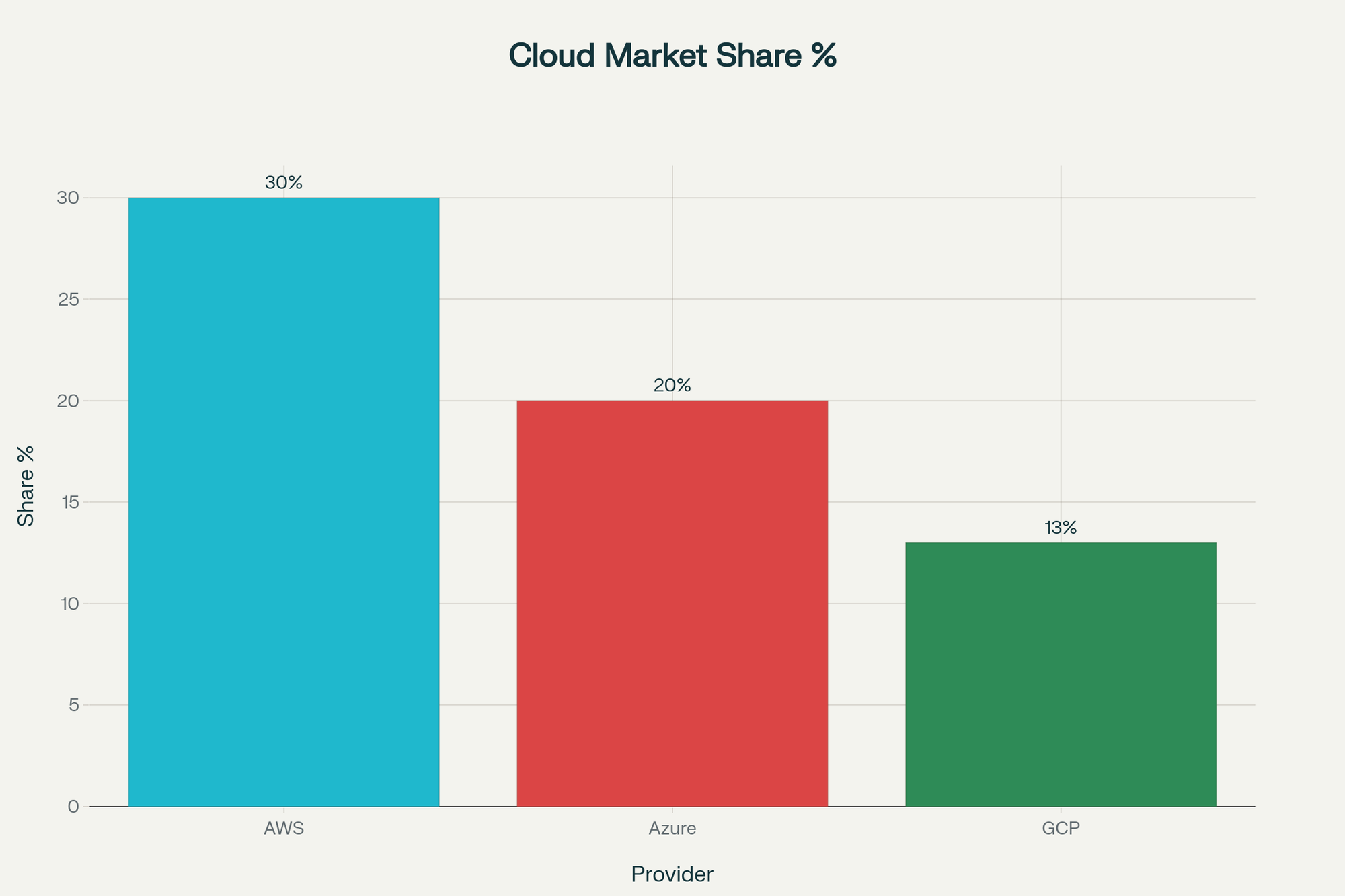
Si la confiabilidad de la nube fuera realmente deficiente, este crecimiento no continuaría.
Recomendaciones prácticas
- La mayoría de las organizaciones: mantengan una estrategia cloud-first, pero diseñen tomando en cuenta las caídas. Inviertan en degradación controlada, respaldos y simulacros de recuperación.
- Cargas críticas: consideren el multi-cloud selectivo solo cuando el costo del downtime supere el overhead.
- Industrias reguladas: usen entornos híbridos solo cuando lo exija la normativa, no el miedo.
Conclusión
La caída de AWS fue grave, costosa y disruptiva. Pero no justifica la nostalgia on-premise ni las estrategias multi-cloud absolutas. La verdad es más simple y más difícil: las caídas son inevitables, la resiliencia es una decisión arquitectónica y la preparación es el verdadero diferenciador.
La lección no es abandonar la nube, sino construir sistemas que fallen con elegancia, se recuperen rápido y aprendan de cada incidente.
No spam, no sharing to third party. Only you and me.




Member discussion