
The October 2025 AWS Outage: What It Really Teaches Us


On October 20, 2025, Amazon Web Services (AWS) experienced one of its most significant outages in years. The US-EAST-1 region in Northern Virginia went offline for nearly 15 hours, disrupting more than 70,000 organizations and generating over 8 million outage reports worldwide. Popular apps like Slack, Snapchat, Fortnite, Roblox, Coinbase, and Robinhood all went down, alongside critical government and banking systems.
As always, the outage sparked debates: some argued for a return to on-premise data centers, others insisted multi-cloud is the answer. Both views miss the real lesson.
Outages Are Inevitable
No system of meaningful scale is immune from failure. AWS has experienced only a handful of major outages in nearly two decades (2011, 2015, 2017, 2019, 2021, 2023, and now 2025). That track record, across billions of compute hours, is remarkably strong. But the complexity of modern digital infrastructure guarantees that outages will happen again—whether in the cloud or on-premise.
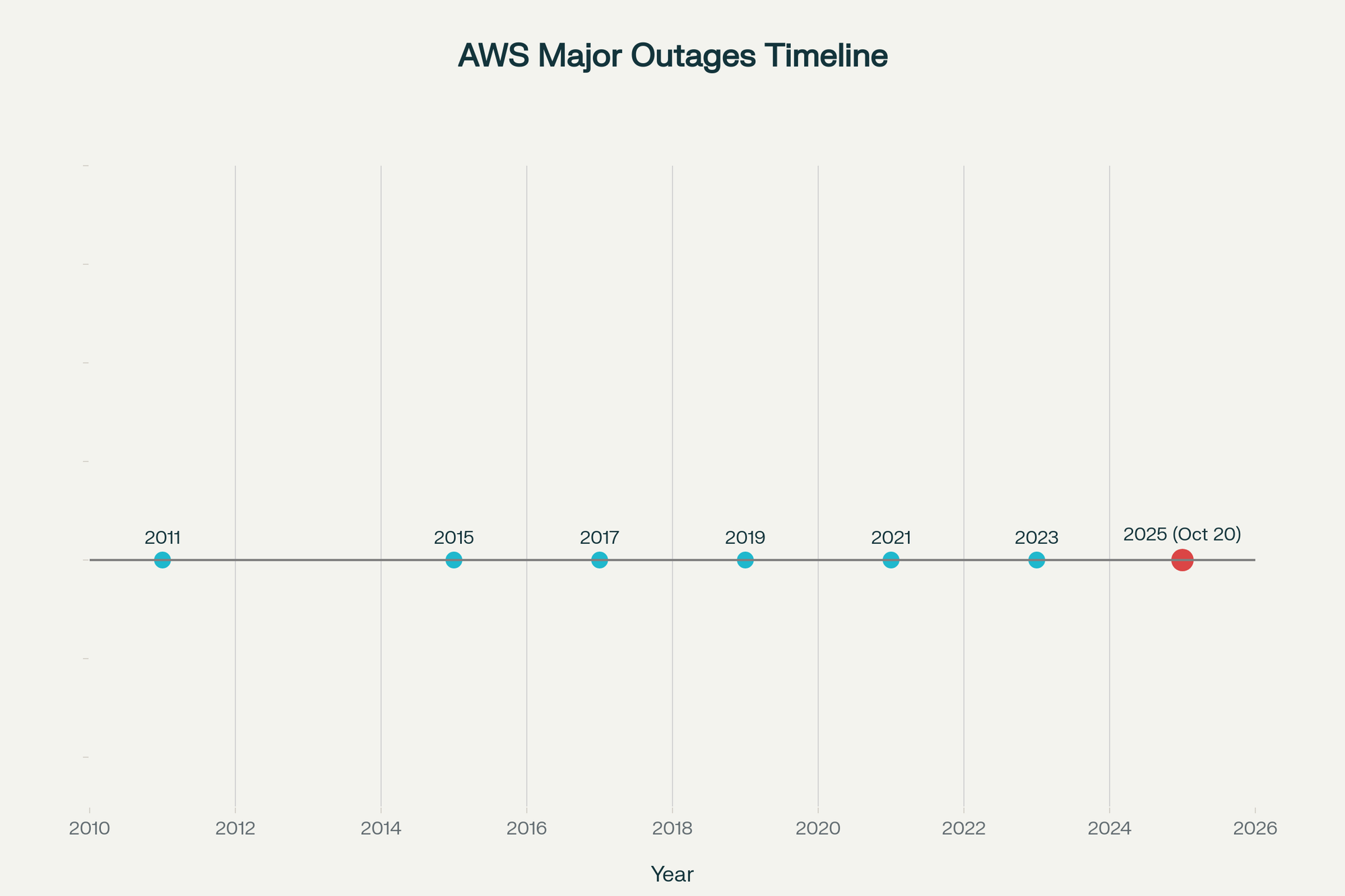
Organizations must design with this inevitability in mind. Architectures, processes, and operating models need to anticipate downtime, not pretend it can be eliminated.
What Happened in US-EAST-1
The root cause was a DNS resolution failure affecting DynamoDB API endpoints. That triggered cascading failures across 113 AWS services. The problem was compounded because US-EAST-1 isn’t just another region; it is AWS’s oldest and most over-subscribed region, with global control-plane dependencies that ripple out worldwide.
Recovery required not just fixing the DNS issue but clearing massive request backlogs and restoring downstream systems—a process that stretched over 15 hours.
The On-Premise Myth
Statistically, cloud outages are rarer and less damaging than what most companies would suffer running their own infrastructure.
Some people suggested this proves we should return to on-premise infrastructure. The data says otherwise:
- AWS and other hyperscalers deliver 99.9%+ uptime guarantees, translating to <9 hours of downtime annually.
- They invest billions—$82 billion in Q3 2024 alone—in redundancy and security.
- Most organizations cannot match that resilience. Building redundant on-premise data centers, hiring specialized staff, and maintaining disaster recovery processes is prohibitively expensive.
Statistically, cloud outages are rarer and less damaging than what most companies would suffer running their own infrastructure.
The Multi-Cloud Complexity Trap
True active-active multi-cloud is rare, expensive, and often unnecessary.
Others claim the answer is multi-cloud. While spreading workloads across providers can reduce lock-in and diversify risk, it comes with serious trade-offs:
- Costs: Specialized staff, tooling, and lost discounts.
- Complexity: 73% of organizations say multi-cloud increased operational complexity.
- Interoperability: Different APIs, formats, and security models.
Most so-called multi-cloud strategies are simply splitting workloads across clouds, not running the same workload redundantly. True active-active multi-cloud is rare, expensive, and often unnecessary.
The Real Lessons
This outage teaches us more valuable lessons than “go on-prem” or “go multi-cloud everywhere.”
- Architecture matters more than location. Design for full region failure, not just availability zone redundancy. Multi-region or pilot-light setups are essential for critical workloads. For example, at Oka we made an intentional decision to use US-EAST-2 as our primary region instead of US-EAST-1, knowing that US-EAST-1 was overpopulated and posed higher risk. This decision limited our business impact during the outage. Still, some external dependencies that lived in US-EAST-1 created friction—proving that while architecture can reduce exposure, it cannot eliminate failure entirely.
- Cascading dependencies are the enemy. As with the 2021 Facebook outage and the 2024 CrowdStrike incident, tightly coupled systems fail together. Mapping dependencies and testing failure modes is critical.
- Preparedness beats theory. Organizations that regularly test disaster recovery recover up to 50% faster. Chaos engineering and realistic drills pay off more than theoretical redundancy.
- Cost-benefit analysis is key. Outages are expensive—estimates for this one range from $38M to $581M in insured losses and $75M per hour in business impact—but the cost of building equivalent on-premise resilience is far higher.
Cloud Market Reality
Despite headlines, cloud adoption keeps accelerating. The global cloud market is growing 25% annually and projected to exceed $400 billion this year. AWS (30%), Azure (20%), and GCP (13%) dominate because their economies of scale, global infrastructure, and R&D speed are unmatched.
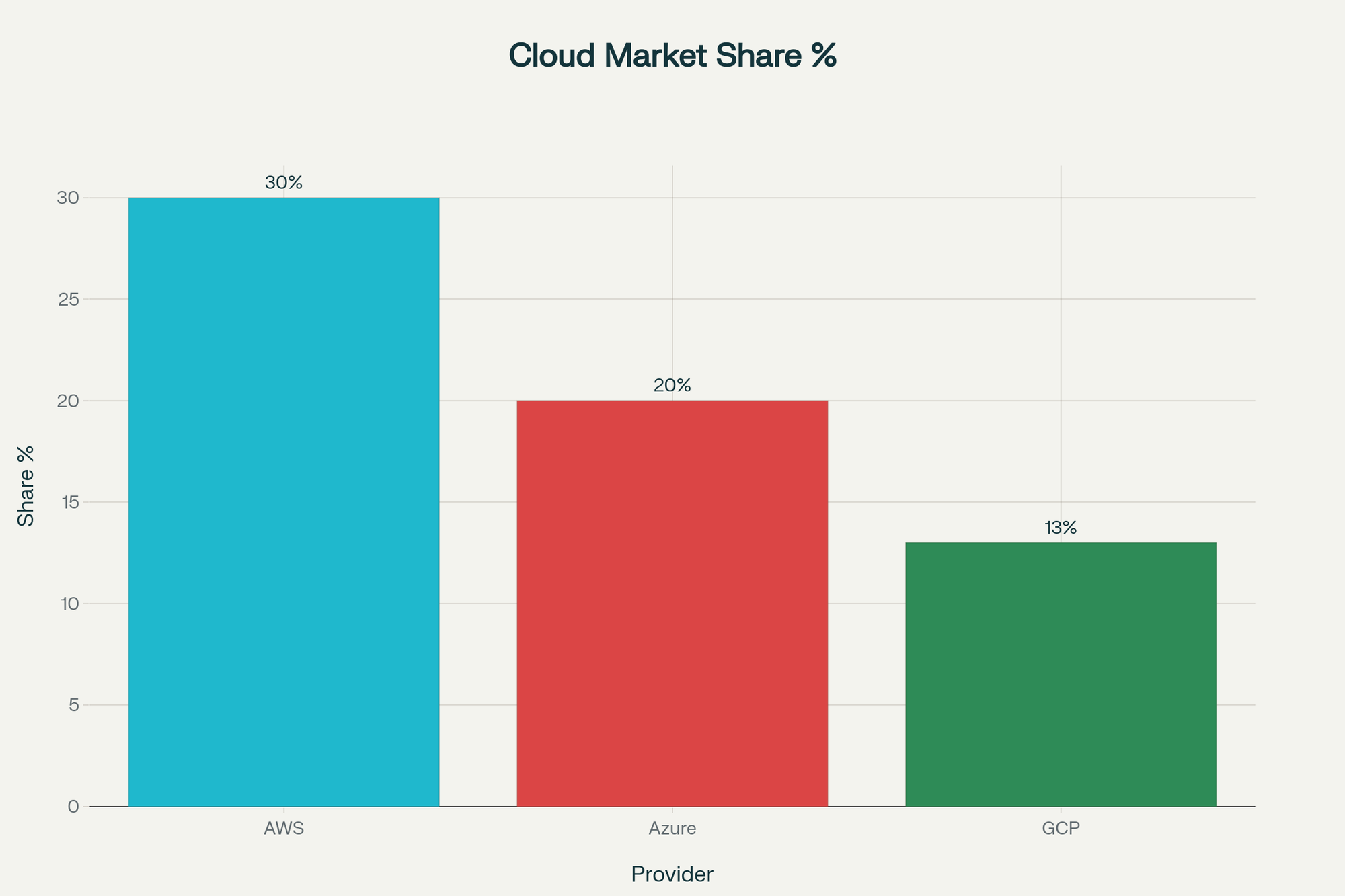
If cloud reliability were fundamentally flawed, this growth would not continue.
Practical Recommendations
- Most organizations: Stay cloud-first, but architect for regional failure. Invest in graceful degradation, backups, and DR drills.
- Mission-critical workloads: Consider selective multi-cloud only when downtime costs exceed the overhead.
- Regulated industries: Use hybrid only where compliance demands it, not fear.
Conclusion
The October 2025 AWS outage was serious, costly, and disruptive. But it doesn’t validate on-prem nostalgia or blanket multi-cloud strategies. The truth is simpler and harder: outages are inevitable, resilience is an architectural choice, and preparedness is the real differentiator.
The lesson is not to abandon the cloud but to build systems that fail gracefully, recover quickly, and learn from every incident.
No spam, no sharing to third party. Only you and me.




Member discussion